DARPA LINC Phase 0
Learning Introspective Control for safety-critical field robots

Overview
In DARPA Learning Introspective Control (LINC) Phase 0, we explore how learning-based Safety Enforcers can enable shared autonomy for safety-critical field robots, by intervening only when necessary, while preserving operator intent and avoiding disruptive or surprising behaviors.
Specifically, we developed and deployed a learning-based safety filter for a hybrid tracked robot operating across challenging terrains (wedge, single-track incline, narrowing corridor, and chicane), culminating in a fully integrated final field test under unmodeled disturbances.
A central design objective of the program is robustness under adversarial and degraded conditions. During deployment, adversarial disturbances may corrupt or disable visual sensing and induce actuator-level degradation. As a result, all Safety Enforcers are trained without camera observations, and must remain effective under partial actuaion loss or altered actuator dynamics. The resulting safety policy relies exclusively on proprioceptive state (e.g., IMU, joint states, velocities), ensuring safe operation even when vision is unavailable and actuation is imperfect.
Key contributions:
- Minimal task disruption: maintained safety while preserving operator intent.
- Not only did not impede progress, but improved challenging terrain traversal.
- Novice-driver friendly: operator can focus on the task, safety is automatic.
System Overview: Learning Introspective Control
The Safety Enforcer continuously monitors the robot state and operator commands using a learned safety critic $Q^\text{safety}$, intervening only when the proposed action would violate safety constraints. Rather than issuing aggressive overrides, the system computes the closest safe action to minimize disruption during shared autonomy.


Learning-Based Safety Filtering
The Safety Enforcer policy was trained using an adversarial reinforcement learning framework inspired by ISAACS (Hsu* et al., 2023), allowing the system to reason over worst-case disturbances while optimizing safe behavior.
Unlike rule-based safety layers, the learned policy captures nonlinear interactions between robot dynamics, terrain geometry, and control actions.


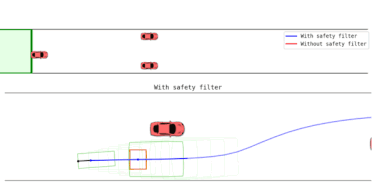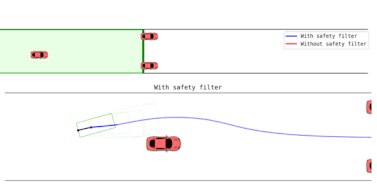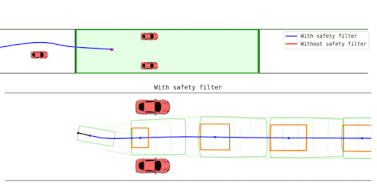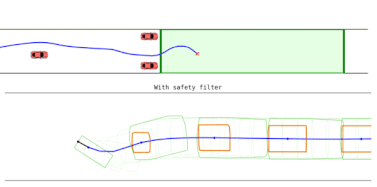
Featured Results: Wedge Terrain Traversal
The wedge terrain represents a high-risk scenario involving large angle variations and potential slam events. With LINC enabled, the robot automatically modulates flipper angles and forward velocity, allowing the operator to command high-level intent (e.g., maximum forward speed) while maintaining safety.



Additional Scenarios: Single-Track Incline
On steep inclines, the Safety Enforcer prevents toppling by modulating forward velocity and halting motion when safety thresholds are exceeded. Operators can adjust acceptable risk levels to continue traversal when appropriate.


Final Field Test: Unified Safety Enforcer
In the final evaluation, a single unified Safety Enforcer was deployed across all terrains without mode switching. The system remained robust even under unmodeled disturbances, including a pendulum payload attached to the robot.

Takeaways
This project demonstrates how learning-based safety mechanisms can be:
- Effective: preventing failure modes such as toppling, slamming, and collisions
- Human-centered: preserving operator intent with minimal, predictable intervention
- Robust: generalizing across terrains and unmodeled disturbances
The techniques developed here inform my broader research on safe reinforcement learning and real-world deployment of autonomous systems.