ISAACS and Gameplay Filters
Safety Filter synthesis and deployment for high-order dynamical systems
ISAACS
ISAACS (Iterative Soft Adversarial Actor-Critic for Safety) (Hsu* et al., 2023) is a new game-theoretic reinforcement learning scheme for approximate safety analysis, whose simulation-trained control policies can be efficiently converted at runtime into robust safety-certified control strategies, allowing robots to plan and operate with safety guarantees in the physical world.
Gameplay Filters

The gameplay filter (Nguyen* et al., 2024) is a new class of predictive safety filters, offering a general approach for runtime robot safety based on game-theoretic reinforcement learning and the core principles of safety filters. Our method learns a best-effort safety policy and a worst-case sim-to-real gap in simulation, and then uses their interplay to inform the robot’s real-time decisions on how and when to preempt potential safety violations.
Learn from adversity


Never lose a game
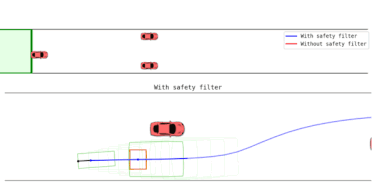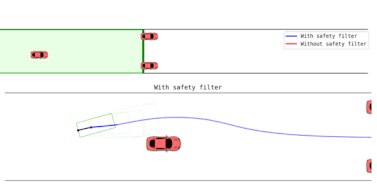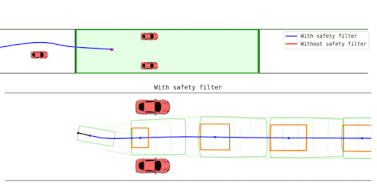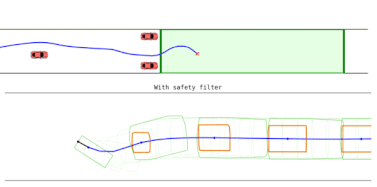
At runtime, the learned player strategies become part of a safety filter, which allows the robot to pursue its task-specific goals or learn a new policy as long as safety is not in jeopardy, but intervenes as needed to prevent future safety violations.

To decide when and how to intervene, the gameplay filter continually imagines (simulates) hypothetical games between the two learned agents after each candidate task action: if taking the proposed action leads to the robot losing the safety game against the learned adversarial environment, the action is rejected and replaced by the learned safety policy.
Results
1. Tugging Forces and Irregular Terrain Evaluation
We evaluate the Gameplay Filters on two quadruped robot platforms, Unitree Go2 and Ghost Robotics S40, across two experimental settings:
- Matched ODD (50 N tugging force): A disturbance consistent with the training Operational Design Domain (ODD), designed to assess whether the Gameplay Filter can maintain robust safety without excessively hindering task execution.
- Unmodeled terrain: A deployment scenario outside the training distribution, used to evaluate whether the Gameplay Filter can preserve zero-shot safety under unmodeled conditions.
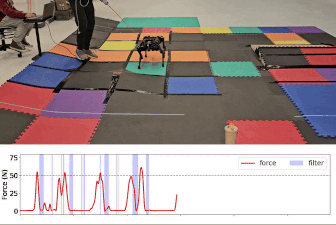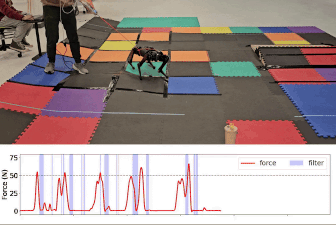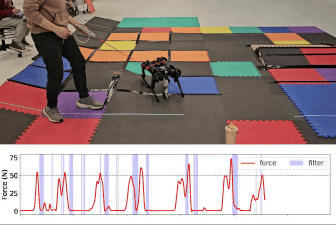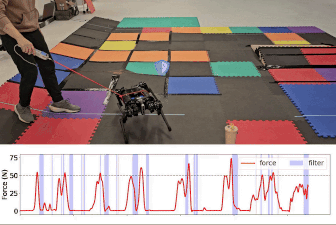
Gameplay filter on unmodeled terrain
Gameplay filter under tugging force
Baseline comparison: Safety critic filter and unfiltered task policy
2. Implicit robustness against degradation
In this demonstration, the rear right abduction motor was broken. The robot’s task policy and safety filter were unaware of this.
Similarly, when the motors of the Unitree Go2 were noticeably degraded, with incorrect encoder readings and dampened actuation performance during the CoRL 2024 demo, the manufacturer’s built-in controller could no longer stabilize the robot, causing it to fail on its own.
Despite this, our Gameplay Filters solution continued to function, demonstrating strong robustness to real-world degradation and adversarial conditions.
3. Tackling large sim-to-real gap
In this demonstration, we train and deploy an RL-driven locomotion task policy on the Unitree Go2 robot with large sim-to-real gap. When deployed on the robot, the task policy causes the robot to flip over. Deploying gameplay filter allows the robot to complete the sequence of task actions without falling.
Takeaway
Gameplay filters allow robots to maintain robust zero-shot safety across deployment conditions with minimal impact on task performance.
- It only overrides unsafe actions that would cause a safety failure for some realization of uncertainty.
- Only requires a single trajectory rollout at each control cycle, enabling runtime safety filtering.
- To our knowledge, this is the first successful demonstration of a full-order safety filter for legged robots (36-D).
Key contributions:
- Scalable: The filter’s neural network makes it suitable for challenging robotic settings like walking on abrupt terrain and under strong forces.
- General: A gameplay filter can be synthesized automatically for any robotic system. All you need is a (black-box) dynamics model.
- Robust: The gameplay filter actively learns and explicitly predicts dangerous discrepancies between the modeled and real dynamics.