publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2025
- Provably Optimal Reinforcement Learning under Safety FilteringDonggeon David Oh*, Duy P. Nguyen*, Haimin Hu, and 1 more author2025
Recent advances in reinforcement learning (RL) enable its use on increasingly complex tasks, but the lack of formal safety guarantees still limits its application in safety-critical settings. A common practical approach is to augment the RL policy with a safety filter that overrides unsafe actions to prevent failures during both training and deployment. However, safety filtering is often perceived as sacrificing performance and hindering the learning process. We show that this perceived safety-performance tradeoff is not inherent and prove, for the first time, that enforcing safety with a sufficiently permissive safety filter does not degrade asymptotic performance. We formalize RL safety with a safety-critical Markov decision process (SC-MDP), which requires categorical, rather than high-probability, avoidance of catastrophic failure states. Additionally, we define an associated filtered MDP in which all actions result in safe effects, thanks to a safety filter that is considered to be a part of the environment. Our main theorem establishes that (i) learning in the filtered MDP is safe categorically, (ii) standard RL convergence carries over to the filtered MDP, and (iii) any policy that is optimal in the filtered MDP-when executed through the same filter-achieves the same asymptotic return as the best safe policy in the SC-MDP, yielding a complete separation between safety enforcement and performance optimization. We validate the theory on Safety Gymnasium with representative tasks and constraints, observing zero violations during training and final performance matching or exceeding unfiltered baselines. Together, these results shed light on a long-standing question in safety-filtered learning and provide a simple, principled recipe for safe RL: train and deploy RL policies with the most permissive safety filter that is available.
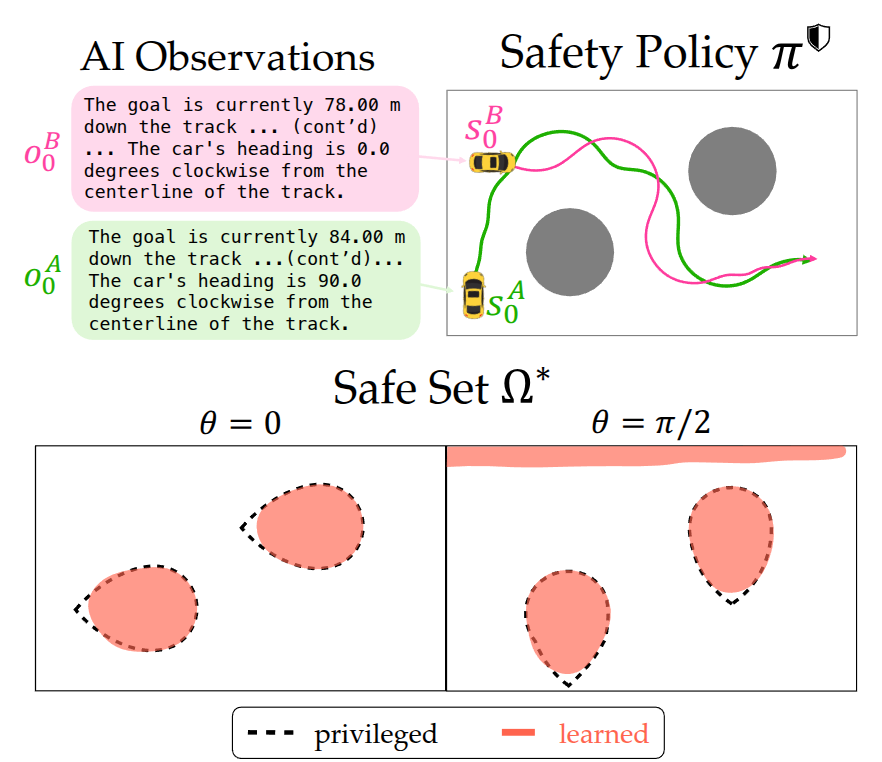
- From Refusal to Recovery: A Control-Theoretic Approach to Generative AI GuardrailsRavi Pandya, Madison Bland, Duy P. Nguyen, and 3 more authors2025
Generative AI systems are increasingly assisting and acting on behalf of end users in practical settings, from digital shopping assistants to next-generation autonomous cars. In this context, safety is no longer about blocking harmful content, but about preempting downstream hazards like financial or physical harm. Yet, most AI guardrails continue to rely on output classification based on labeled datasets and human-specified criteria,making them brittle to new hazardous situations. Even when unsafe conditions are flagged, this detection offers no path to recovery: typically, the AI system simply refuses to act–which is not always a safe choice. In this work, we argue that agentic AI safety is fundamentally a sequential decision problem: harmful outcomes arise from the AI system’s continually evolving interactions and their downstream consequences on the world. We formalize this through the lens of safety-critical control theory, but within the AI model’s latent representation of the world. This enables us to build predictive guardrails that (i) monitor an AI system’s outputs (actions) in real time and (ii) proactively correct risky outputs to safe ones, all in a model-agnostic manner so the same guardrail can be wrapped around any AI model. We also offer a practical training recipe for computing such guardrails at scale via safety-critical reinforcement learning. Our experiments in simulated driving and e-commerce settings demonstrate that control-theoretic guardrails can reliably steer LLM agents clear of catastrophic outcomes (from collisions to bankruptcy) while preserving task performance, offering a principled dynamic alternative to today’s flag-and-block guardrails.

2024
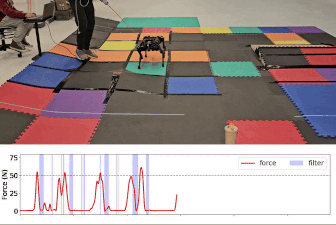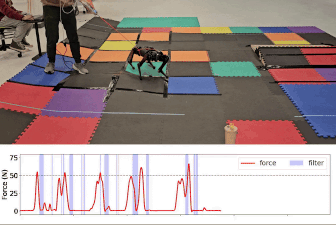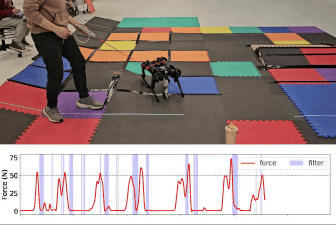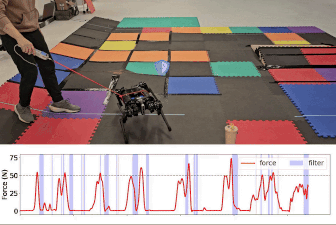
- Gameplay Filters: Robust Zero-Shot Safety through Adversarial ImaginationDuy P. Nguyen*, Kai-Chieh Hsu*, Wenhao Yu, and 2 more authorsIn 8th Annual Conference on Robot Learning, 2024
Despite the impressive recent advances in learning-based robot control, ensuring robustness to out-of-distribution conditions remains an open challenge. Safety filters can, in principle, keep arbitrary control policies from incurring catastrophic failures by overriding unsafe actions, but existing solutions for complex (e.g., legged) robot dynamics do not span the full motion envelope and instead rely on local, reduced-order models. These filters tend to overly restrict agility and can still fail when perturbed away from nominal conditions. This paper presents the gameplay filter, a new class of predictive safety filter that continually plays out hypothetical matches between its simulation-trained safety strategy and a virtual adversary co-trained to invoke worst-case events and sim-to-real error, and precludes actions that would cause failures down the line. We demonstrate the scalability and robustness of the approach with a first-of-its-kind full-order safety filter for (36-D) quadrupedal dynamics. Physical experiments on two different quadruped platforms demonstrate the superior zero-shot effectiveness of the gameplay filter under large perturbations such as tugging and unmodeled terrain. Experiment videos and open-source software are available online: https://saferobotics.org/research/gameplay-filter
- MAGICS: Adversarial RL with Minimax Actors Guided by Implicit Critic Stackelberg for Convergent Neural Synthesis of Robot SafetyJustin Wang, Haimin Hu, Duy Phuong Nguyen, and 1 more author2024
While robust optimal control theory provides a rigorous framework to compute robot control policies that are provably safe, it struggles to scale to high-dimensional problems, leading to increased use of deep learning for tractable synthesis of robot safety. Unfortunately, existing neural safety synthesis methods often lack convergence guarantees and solution interpretability. In this paper, we present Minimax Actors Guided by Implicit Critic Stackelberg (MAGICS), a novel adversarial reinforcement learning (RL) algorithm that guarantees local convergence to a minimax equilibrium solution. We then build on this approach to provide local convergence guarantees for a general deep RL-based robot safety synthesis algorithm. Through both simulation studies on OpenAI Gym environments and hardware experiments with a 36-dimensional quadruped robot, we show that MAGICS can yield robust control policies outperforming the state-of-the-art neural safety synthesis methods.

2023
- ISAACS: Iterative Soft Adversarial Actor-Critic for SafetyKai-Chieh Hsu*, Duy Phuong Nguyen*, and Jaime Fernàndez FisacIn Proceedings of The 5th Annual Learning for Dynamics and Control Conference, 15–16 jun 2023
The deployment of robots in uncontrolled environments requires them to operate robustly under previously unseen scenarios, like irregular terrain and wind conditions. Unfortunately, while rigorous safety frameworks from robust optimal control theory scale poorly to high-dimensional nonlinear dynamics, control policies computed by more tractable "deep" methods lack guarantees and tend to exhibit little robustness to uncertain operating conditions. This work introduces a novel approach enabling scalable synthesis of robust safety-preserving controllers for robotic systems with general nonlinear dynamics subject to bounded modeling error by combining game-theoretic safety analysis with adversarial reinforcement learning in simulation. Following a soft actor-critic scheme, a safety-seeking fallback policy is co-trained with an adversarial "disturbance" agent that aims to invoke the worst-case realization of model error and training-to-deployment discrepancy allowed by the designer’s uncertainty. While the learned control policy does not intrinsically guarantee safety, it is used to construct a real-time safety filter (or shield) with robust safety guarantees based on forward reachability rollouts. This shield can be used in conjunction with a safety-agnostic control policy, precluding any task-driven actions that could result in loss of safety. We evaluate our learning-based safety approach in a 5D race car simulator, compare the learned safety policy to the numerically obtained optimal solution, and empirically validate the robust safety guarantee of our proposed safety shield against worst-case model discrepancy.
- Sim-to-Lab-to-Real: Safe reinforcement learning with shielding and generalization guaranteesKai-Chieh Hsu, Allen Z. Ren, Duy P. Nguyen, and 2 more authorsArtificial Intelligence, 2023
Safety is a critical component of autonomous systems and remains a challenge for learning-based policies to be utilized in the real world. In particular, policies learned using reinforcement learning often fail to generalize to novel environments due to unsafe behavior. In this paper, we propose Sim-to-Lab-to-Real to bridge the reality gap with a probabilistically guaranteed safety-aware policy distribution. To improve safety, we apply a dual policy setup where a performance policy is trained using the cumulative task reward and a backup (safety) policy is trained by solving the Safety Bellman Equation based on Hamilton-Jacobi (HJ) reachability analysis. In Sim-to-Lab transfer, we apply a supervisory control scheme to shield unsafe actions during exploration; in Lab-to-Real transfer, we leverage the Probably Approximately Correct (PAC)-Bayes framework to provide lower bounds on the expected performance and safety of policies in unseen environments. Additionally, inheriting from the HJ reachability analysis, the bound accounts for the expectation over the worst-case safety in each environment. We empirically study the proposed framework for ego-vision navigation in two types of indoor environments with varying degrees of photorealism. We also demonstrate strong generalization performance through hardware experiments in real indoor spaces with a quadrupedal robot. See this https URL for supplementary material.

2022
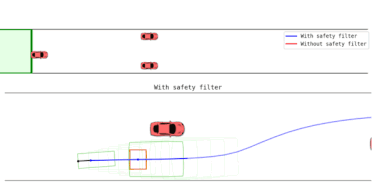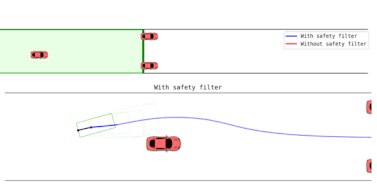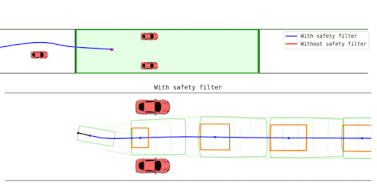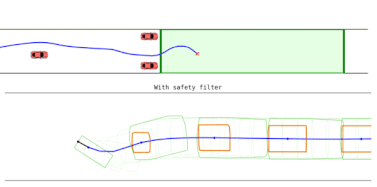
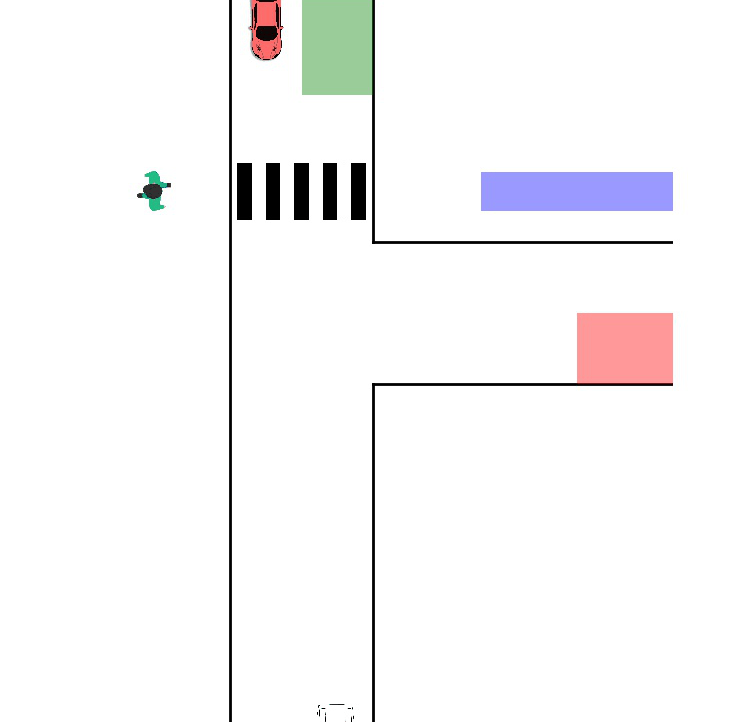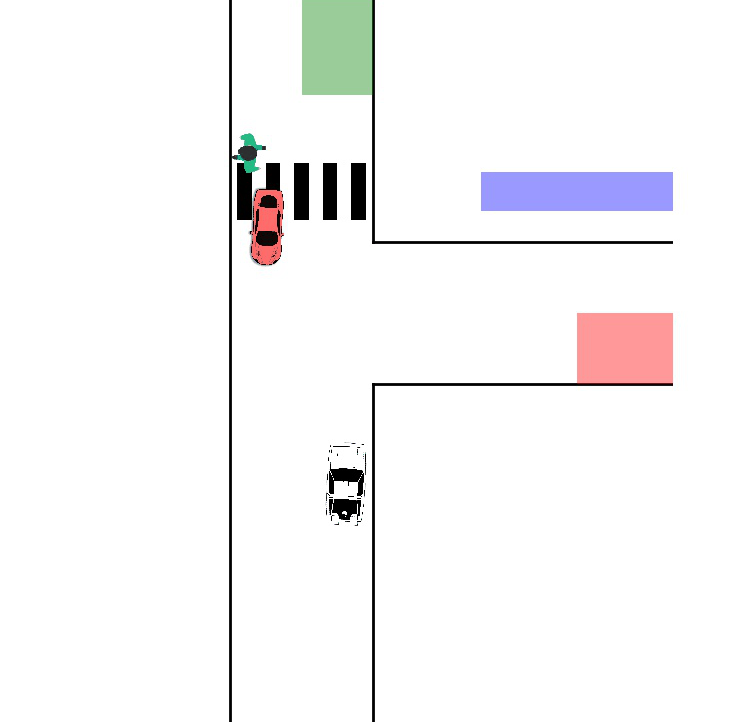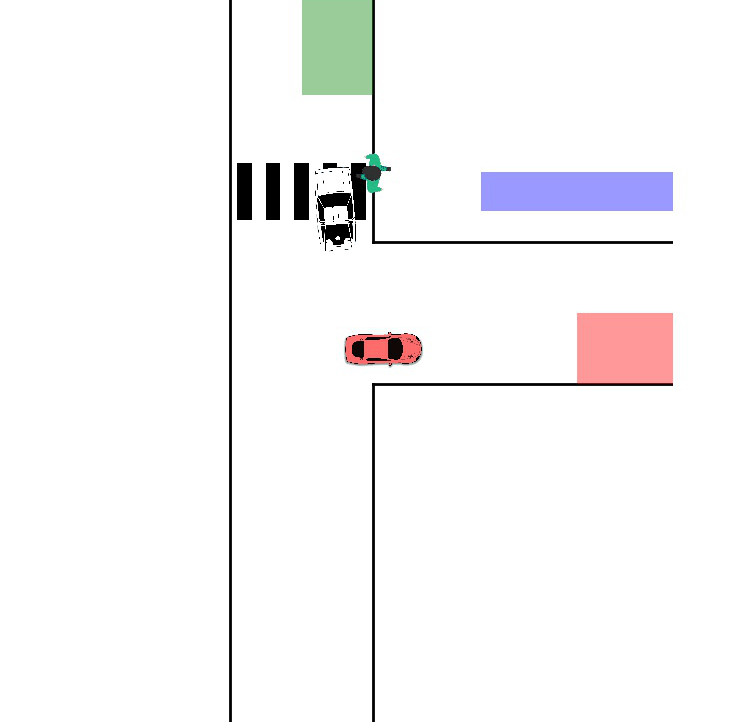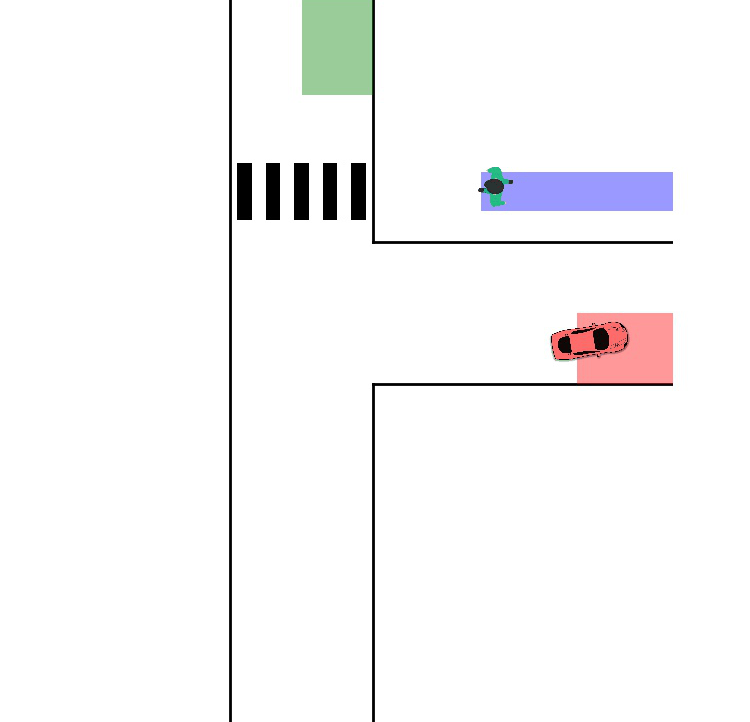
- Back to the Future: Efficient, Time-Consistent Solutions in Reach-Avoid GamesDennis R. Anthony, Duy P. Nguyen, David Fridovich-Keil, and 1 more authorIn 2022 International Conference on Robotics and Automation (ICRA), 2022
We study the class of reach-avoid dynamic games in which multiple agents interact noncooperatively, and each wishes to satisfy a distinct target criterion while avoiding a failure criterion. Reach-avoid games are commonly used to express safety-critical optimal control problems found in mobile robot motion planning. Here, we focus on finding time-consistent solutions, in which future motion plans remain optimal even when a robot diverges from the plan early on due to, e.g., intrinsic dynamic uncertainty or extrinsic environment disturbances. Our main contribution is a computationally-efficient algorithm for multi-agent reach-avoid games which renders time-consistent solutions for all players. We demonstrate our approach in two- and three-player simulated driving scenarios, in which our method provides safe control strategies for all agents.
2020
-
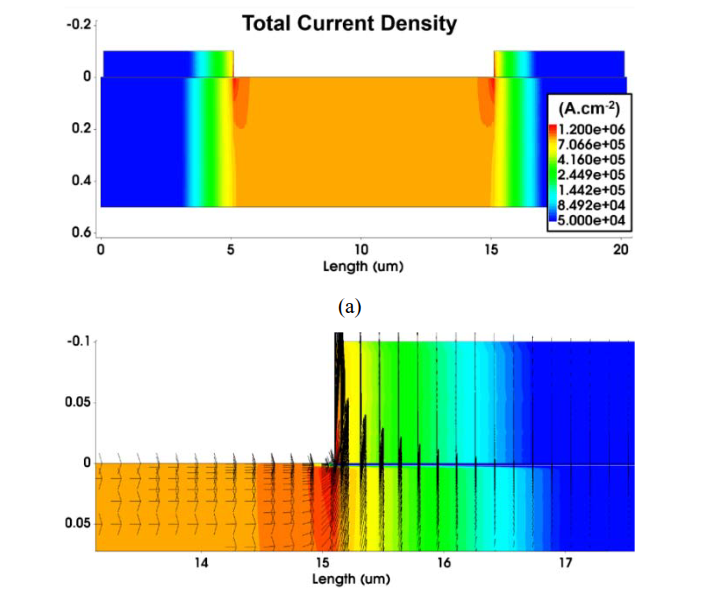 An Investigation of Transmission Line Modeling Test Structure in TCADP.C. Thanh, Duy Nguyen Phuong, Anthony Holland, and 1 more authorIn 2020 4th IEEE Electron Devices Technology Manufacturing Conference (EDTM), 2020
An Investigation of Transmission Line Modeling Test Structure in TCADP.C. Thanh, Duy Nguyen Phuong, Anthony Holland, and 1 more authorIn 2020 4th IEEE Electron Devices Technology Manufacturing Conference (EDTM), 2020As semiconductor devices shrinks down to sub 10nm range, contact resistance has become a significant performance factor that needs to be studied. Existing test structures such as Transmission line model (TLM) structures are no longer sensitive enough to determine the small changes in specific contact resistance (SCR) at confidence level. This paper reports a methodology to determine SCR in a TLM test structure using Sentaurus Technology Computer-Aided Design (TCAD). The tool is demonstrated to be effective to model and characterize test structures with TCAD. An analysis on the correlation between doping concentration and ohmic contact was investigated. The SCR value is calculated from the extracted total resistance using the analytical model of TLM test structure.
2019
-
 Towards a modular and dexterous transhumeral prosthesis based on bio-signals and active visionPhuong Duy Nguyen and Chi Thanh PhamIn 2019 IEEE International Symposium on Measurement and Control in Robotics (ISMCR), 2019
Towards a modular and dexterous transhumeral prosthesis based on bio-signals and active visionPhuong Duy Nguyen and Chi Thanh PhamIn 2019 IEEE International Symposium on Measurement and Control in Robotics (ISMCR), 2019The number of individuals suffering from disability caused by congenital limb deficiency or amputation is on the rise and most commercial prostheses are high in cost, low in dexterity and transradial despite the high demand for transhumeral ones. Studies show that the rejection rate is high and that recipients are dissatisfied with the activity variations and respective reachable performance standards. This paper considers the current limitations of prosthesis and proposes an affordable transhumeral design based on bio-signals and active vision system. The overall mechanical design has 10 degrees of freedom, is fully 3D printed and modular. The system is distributed and support multimodal interaction based on biosignals and active vision system. The prosthesis has configurable level of automation and could autonomously choose the most suitable grip pattern for object handling from a wide range of supported objects.
-
 A hybrid active vision system for real time application running object recognitionDuy Nguyen PhuongIn 2019 2nd International Symposium on Devices, Circuits and Systems (ISDCS), 2019
A hybrid active vision system for real time application running object recognitionDuy Nguyen PhuongIn 2019 2nd International Symposium on Devices, Circuits and Systems (ISDCS), 2019Computer vision is developing fast and be applied to robotics. Active vision system has been researched recently to address problems with saccade movement and real-time realization. The paper proposed the use of a hybrid system consisting of an object recognition model built with MobileNet SSD and an object tracker running Median Flow. This system has proven to work well in real-time application, with an average 15 frames per second and angular speed of 75 degree per second. The system remains stable and robust throughout all experiments. The final design is implemented to control movement of a transhumeral prosthesis through determining object of interest, calibrating wrist according to object position and choosing grip patterns with respective to object characteristics.
2018
-
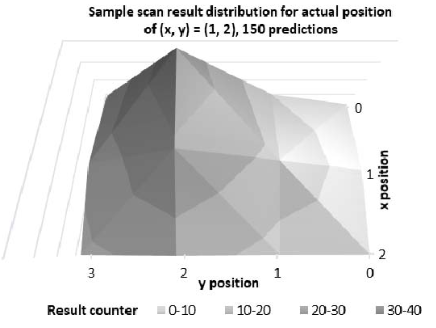 A Hybrid Indoor Localization System Running Ensemble Machine LearningDuy Nguyen Phuong and Thanh Pham ChiIn 2018 IEEE Intl Conf on Parallel Distributed Processing with Applications, Ubiquitous Computing Communications, Big Data Cloud Computing, Social Computing Networking, Sustainable Computing Communications (ISPA/IUCC/BDCloud/SocialCom/SustainCom), 2018
A Hybrid Indoor Localization System Running Ensemble Machine LearningDuy Nguyen Phuong and Thanh Pham ChiIn 2018 IEEE Intl Conf on Parallel Distributed Processing with Applications, Ubiquitous Computing Communications, Big Data Cloud Computing, Social Computing Networking, Sustainable Computing Communications (ISPA/IUCC/BDCloud/SocialCom/SustainCom), 2018The need for localization in various fields of applications and the lack of efficiency in using GPS indoor leads to the development of Indoor Localization Systems. The recent rapid growth of mobile users and Wi-Fi infrastructure of modern buildings enables different methodologies to build high performance indoor localization system with minimum investment. This paper presents a novel model for indoor localization system on Android mobile devices with built-in application running ensemble learning method and artificial neural network. The system performance is enhanced with the implementation of background filters using built-in sensors. Notably, the proposed model is designed to gradually converge to location the longer the runtime. It eventually produces the correct rate of 95 percent for small-room localization with error radius of approximately 0.5 to 1 meter and the convergence time of 10 seconds at best. The developed model can run offline and optimized for embedded systems and Android devices based on pre-built models of Wi-Fi fingerprints.